前言
写一下 ElasticSearch 在 SpringBoot 中的整合,本文实现在 ES 中的单条数据的增删改查功能。
实现
理论部分
RestHighLevelClient
本文我们使用的是 RestHighLevelClient 来实现的。
RestHighLevelClient 是 Elasticsearch 官方提供的 Java 高级 REST 客户端,它基于低级客户端(Low Level REST Client)构建而成,并提供了更多的功能和便利性。
不过,在 Elasticsearch7.15 版本之后,Elasticsearch 官方将它的高级客户端 RestHighLevelClient 标记为弃用状态。同时推出了全新的 Java API 客户端
Elasticsearch Java API Client,该客户端也将在 Elasticsearch8.0 及以后版本中成为官方推荐使用的客户端。
集群、节点、分片、副本概念
1. 概念:
-
集群(Cluster): ES 可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES 可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。 -
节点(Node): 形成集群的每个服务器称为节点。 -
分片(shard):当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当查询的索引分布在多个分片上时,ES 会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。 -
副本(Replia):为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。 -
索引(index): 在 ES 中, 索引是一组文档的集合。
2. 区别:
分片与副本的区别在于:
当分片设置为5,数据量为30G时,ES 会自动帮我们把数据均衡地分配到5个分片上,即每个分片大概有6G数据;当查询数据时,ES 会把查询发送给每个相关的分片,并将结果组合在一起。
而副本,就是对分布在5个分片的数据进行复制。因为分片是把数据进行分割而已,数据依然只有一份,这样的目的是保障查询的高效性,副本则是多复制几份分片的数据,这样的目的是保障数据的高可靠性,防止数据丢失。
注意:
- 索引建立后,分片个数是不可以更改的。
代码部分
pom.xml
在 pom.xml 中引入依赖:
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.14.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.14.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.14.0</version>
</dependency>
注:
- 依赖版本与 ES 服务的版本保持一致,这里我们使用的是
7.14.0版本。
application.yaml
在 application.yaml 配置文件中添加相应配置项:
spring:
elasticsearch:
rest:
uris: localhost:9200
username: elastic
password: 123456
config配置类
package com.langjialing.helloworld.config;
import lombok.SneakyThrows;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.conn.ssl.NoopHostnameVerifier;
import org.apache.http.conn.ssl.TrustStrategy;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.apache.http.impl.nio.reactor.IOReactorConfig;
import org.apache.http.ssl.SSLContextBuilder;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;
import javax.net.ssl.SSLContext;
import java.util.ArrayList;
import java.util.List;
/**
* @author 郎家岭伯爵
* @time 2024/4/16 14:56
*/
@Configuration
public class EsConfig {
@Value("${spring.elasticsearch.rest.uris}")
private String uris;
@Value("${spring.elasticsearch.rest.username}")
private String username;
@Value("${spring.elasticsearch.rest.password}")
private String password;
@Bean(name = "restHighLevelClient")
public RestHighLevelClient restHighLevelClient() {
// 拆分地址
List<HttpHost> hostLists = new ArrayList<>();
String[] hostList = uris.split(",");
for (String addr : hostList) {
hostLists.add(HttpHost.create(addr));
}
// 转换成 HttpHost 数组
HttpHost[] httpHost = hostLists.toArray(new HttpHost[] {});
RestClientBuilder clientBuilder = RestClient.builder(httpHost);
clientBuilder.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@SneakyThrows
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) {
if (!StringUtils.isEmpty(username) && !StringUtils.isEmpty(password)) {
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
UsernamePasswordCredentials credentials = new UsernamePasswordCredentials(username, password);
credentialsProvider.setCredentials(AuthScope.ANY, credentials);
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
}
IOReactorConfig ioReactorConfig = IOReactorConfig.custom().setIoThreadCount(100)
.setConnectTimeout(10000).setSoTimeout(10000).build();
httpClientBuilder.setDefaultIOReactorConfig(ioReactorConfig);
SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null, new TrustStrategy() {
@Override
public boolean isTrusted(java.security.cert.X509Certificate[] arg0, String arg1) {
return true;
}
}).build();
httpClientBuilder.setSSLContext(sslContext);
httpClientBuilder.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE);
return httpClientBuilder;
}
});
return new RestHighLevelClient(clientBuilder);
}
}
增删改查代码
package com.langjialing.helloworld.controlle1;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.admin.cluster.health.ClusterHealthRequest;
import org.elasticsearch.action.admin.cluster.health.ClusterHealthResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.DeleteByQueryRequest;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
/**
* @author 郎家岭伯爵
* @time 2024/4/16 15:07
*/
@RequestMapping("/es")
@RestController
@Slf4j
public class EsController {
@Autowired
private RestHighLevelClient restHighLevelClient;
@GetMapping("/createIndex")
public void createIndex(@RequestParam String indexName) throws IOException {
CreateIndexRequest request = new CreateIndexRequest(indexName);
request.settings(Settings
.builder()
.put("index.number_of_shards", 5)
.put("index.number_of_replicas", 3));
// 设置文档字段类型的mapping信息。这里设置一个GeoPoint类型
String mapping = "{\n" +
" \"properties\": {\n" +
" \"location\": {\n" +
" \"type\": \"geo_point\"\n" +
" }\n" +
" }\n" +
"}";
request.mapping(mapping, XContentType.JSON);
final CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
}
@GetMapping("/indexExist")
public void indexExist(@RequestParam String indexName) throws IOException {
GetIndexRequest exist=new GetIndexRequest(indexName);
boolean response=restHighLevelClient.indices().exists(exist, RequestOptions.DEFAULT);
if (response){
log.info("索引已存在,无需创建!");
} else {
log.info("索引不存在,创建索引!");
}
}
@GetMapping("/getNodeNumbers")
public int getNodeNumbers() throws IOException {
// 构建 ClusterHealthRequest 请求
ClusterHealthRequest request = new ClusterHealthRequest();
// 设置请求参数
request.timeout("30s");
// 执行请求,并获取响应
ClusterHealthResponse response = restHighLevelClient.cluster().health(request, RequestOptions.DEFAULT);
// 获取集群中的节点数量
int numberOfNodes = response.getNumberOfNodes();
return numberOfNodes;
}
@PostMapping("/t1")
public void test1(@RequestBody JSONObject jsonObject) throws IOException {
indexDocument("langjialing_index", jsonObject.getString("id"), jsonObject.toJSONString());
}
@GetMapping("/get/byId")
public void getById(@RequestParam String id) throws IOException{
getDocumentById("langjialing_index", id);
}
@PostMapping("/get/byQuery")
public void getByQuery(@RequestBody JSONObject jsonObject) throws IOException{
getDocumentByQuery("langjialing_index", jsonObject.getString("name"));
}
@PostMapping("/delete/byQuery")
public void deleteByQuery(@RequestBody JSONObject jsonObject) throws IOException{
deleteDocumentsByQuery("langjialing_index", jsonObject.getString("name"));
}
@GetMapping("/delete/byId")
public void deleteById(@RequestParam String id) throws IOException{
deleteDocumentById("langjialing_index", id);
}
@PostMapping("/update/byId")
public void updateById(@RequestBody JSONObject jsonObject) throws IOException{
updateDocumentById("langjialing_index", jsonObject.getString("id"), jsonObject);
}
/**
* 创建索引并写入数据。
* @param index
* @param id
* @param jsonSource
* @throws IOException
*/
private void indexDocument(String index, String id, String jsonSource) throws IOException{
final IndexRequest request = new IndexRequest(index)
.id(id)
.source(jsonSource, XContentType.JSON);
final IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
log.info("Document indexed successfully. ID:{}.", response.getId());
}
/**
* 根据索引和数据ID查询文档。
* @param index
* @param id
* @throws IOException
*/
private void getDocumentById(String index, String id) throws IOException{
final GetRequest request = new GetRequest(index, id);
final GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
if (response.isExists()){
log.info("Document found:{}.", response.getSourceAsString());
} else {
log.info("Document not found.");
}
}
/**
* 根据条件查询文档。
* @param index
* @param name
* @throws IOException
*/
private void getDocumentByQuery(String index, String name) throws IOException{
// 创建SearchRequest对象
final SearchRequest request = new SearchRequest(index);
// 创建SearchSourceBuilder对象,用于构建查询条件
final SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termQuery("name", name));
sourceBuilder.from(0);
sourceBuilder.size(10);
// 将SearchSourceBuilder对象设置到SearchRequest中
request.source(sourceBuilder);
log.info("Search Query:{}.", sourceBuilder);
// 执行搜索操作
final SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
// 根据实际情况处理搜索结果。
log.info("Search results:{}.", response);
Arrays.stream(response.getHits().getHits()).forEach(hit -> log.info(hit.getSourceAsString()));
}
/**
* 根据条件删除文档。
* @param index
* @param name
* @throws IOException
*/
private void deleteDocumentsByQuery(String index, String name) throws IOException{
final DeleteByQueryRequest request = new DeleteByQueryRequest(index);
request.setQuery(QueryBuilders.termQuery("name", name));
final BulkByScrollResponse response = restHighLevelClient.deleteByQuery(request, RequestOptions.DEFAULT);
log.info("Document deleted by query successfully. Deleted:{}.", response.getDeleted());
}
/**
* 根据ID删除文档。
* @param index
* @param id
* @throws IOException
*/
private void deleteDocumentById(String index, String id) throws IOException{
final DeleteRequest request = new DeleteRequest();
request.index(index);
request.id(id);
final DeleteResponse response = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
log.info("Document deleted by id successfully. Deleted:{}.", response.getResult());
}
/**
* 根据ID更新文档。
* @param index
* @param id
* @throws IOException
*/
private void updateDocumentById(String index, String id, JSONObject jsonObject) throws IOException{
final UpdateRequest request = new UpdateRequest();
request.index(index);
request.id(id);
final HashMap<String, Object> map = new HashMap<>(2);
map.put("name", jsonObject.getString("name"));
request.doc(map);
final UpdateResponse response = restHighLevelClient.update(request, RequestOptions.DEFAULT);
log.info("Document update by id successfully. Updated Result:{}.", response.getResult());
}
}
代码测试
这里我们测试一个创建索引的功能,其它功能可自行测试。
- 使用 POSTMAN 调用接口:
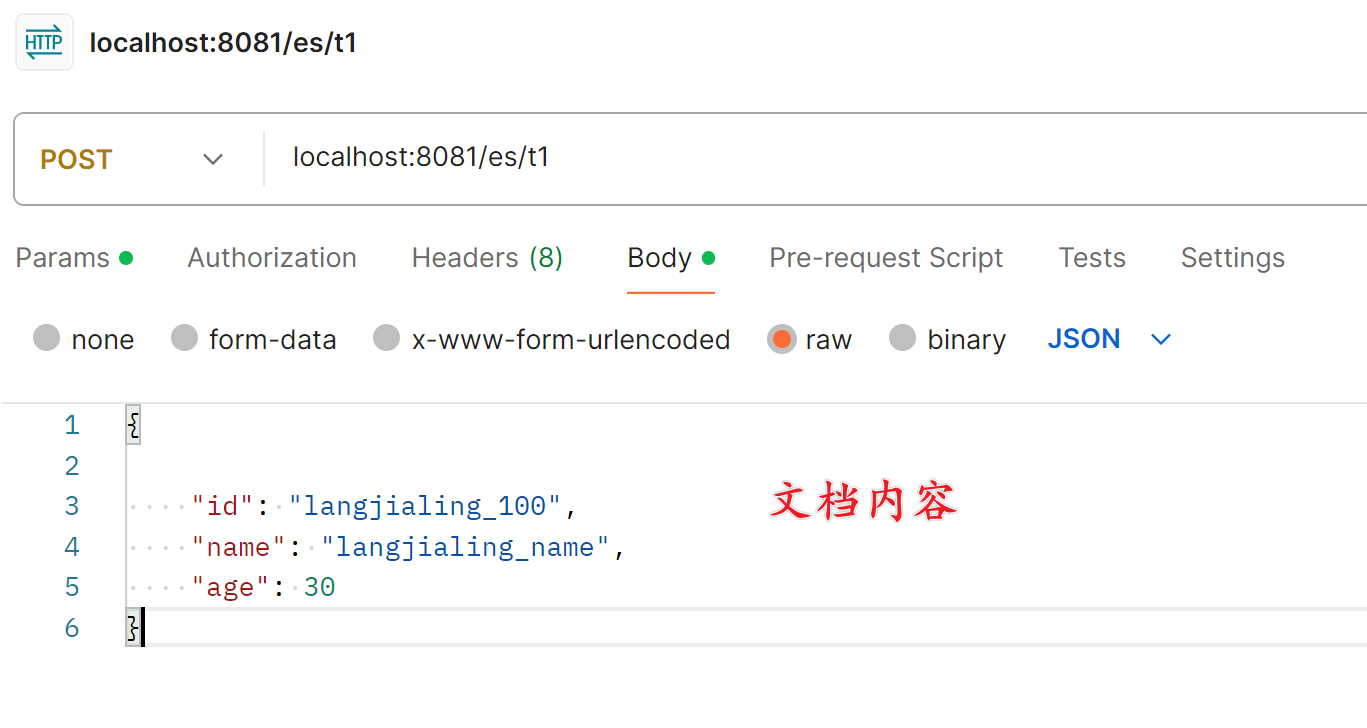
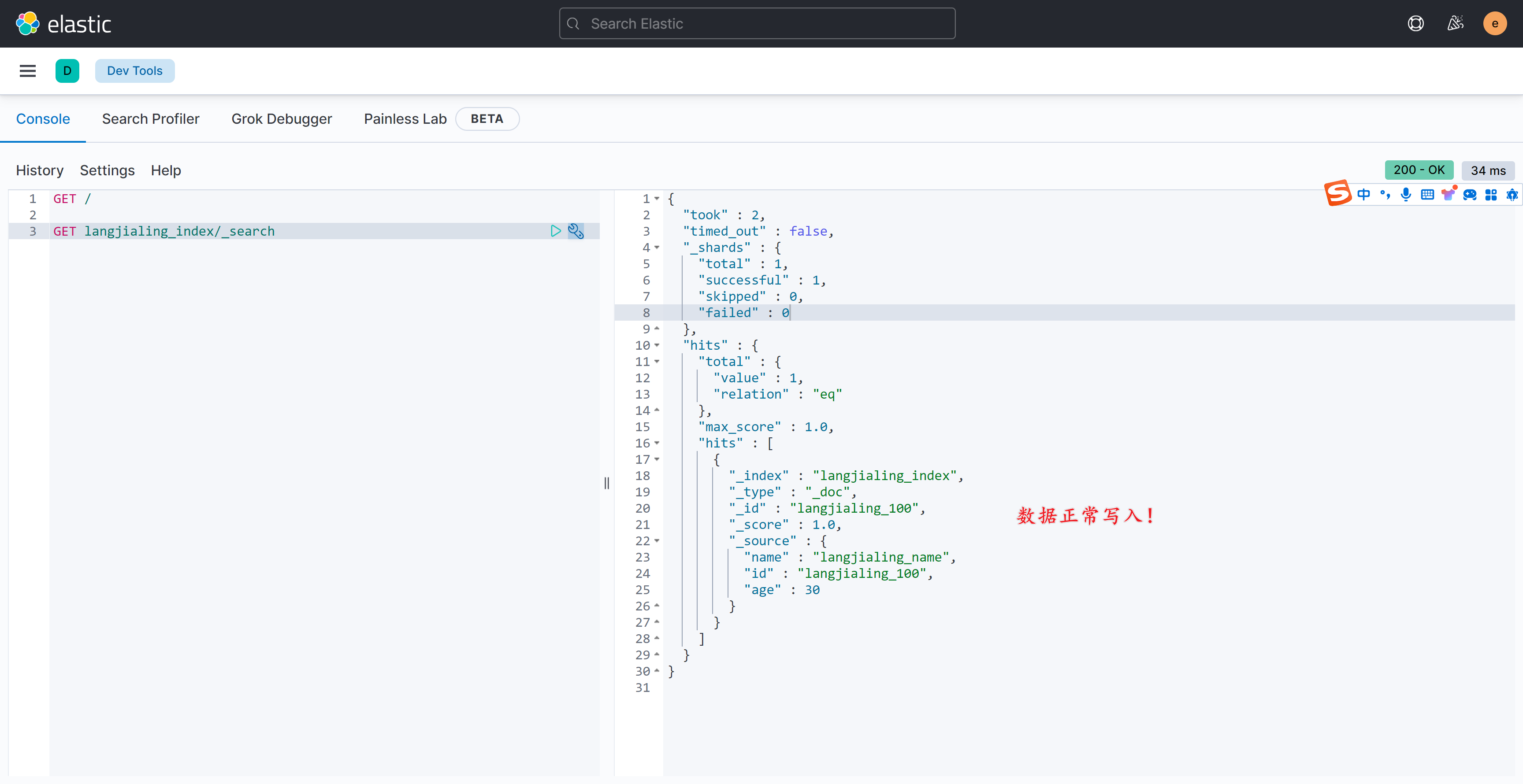
- 在 kibana 中查看数据:
总结
实现下 ElasticSearch 在 SpringBoot 中的单条数据的增删改查功能。