背景
使用线程池创建多线程。
实现
线程池创建方式
创建线程池有两种方式:
- 使用
Executors创建; - 使用
ThreadPoolExecutor创建。
Executors 是对 ThreadPoolExecutor 进行了一层封装,因此使用起来会比较方便。不过阿里的《Java开发手册》建议我们使用 ThreadPoolExecutor 来创建多线程,使用 Executors 创建线程池可能会导致 OOM(OutOfMemory ,内存溢出)。


线程池核心参数
由于线程池使用 ThreadPoolExecutor 进行创建(Executors 是封装 ThreadPoolExecutor 实现的,见上一小节截图),因此我们来看下它的构造方法。
ThreadPoolExecutor 提供了四个构造方法,其中第四个参数最多,为七个参数(但本质上参数个数是一样的,只是传值不同,其它三个分别设置了默认的参数):

我们找到源码来看下其作用:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
其各个参数作用为:
| 序号 | 名称 | 类型 | 含义 |
|---|---|---|---|
| 1 | corePoolSize | int | 核心线程池大小 |
| 2 | maximumPoolSize | int | 最大线程池大小 |
| 3 | keepAliveTime | long | 线程最大空闲时间 |
| 4 | unit | TimeUnit | 时间单位 |
| 5 | workQueue | BlockingQueue |
线程等待队列 |
| 6 | threadFactory | ThreadFactory | 线程创建工厂 |
| 7 | handler | RejectedExecutionHandler | 拒绝策略 |
线程池执行流程
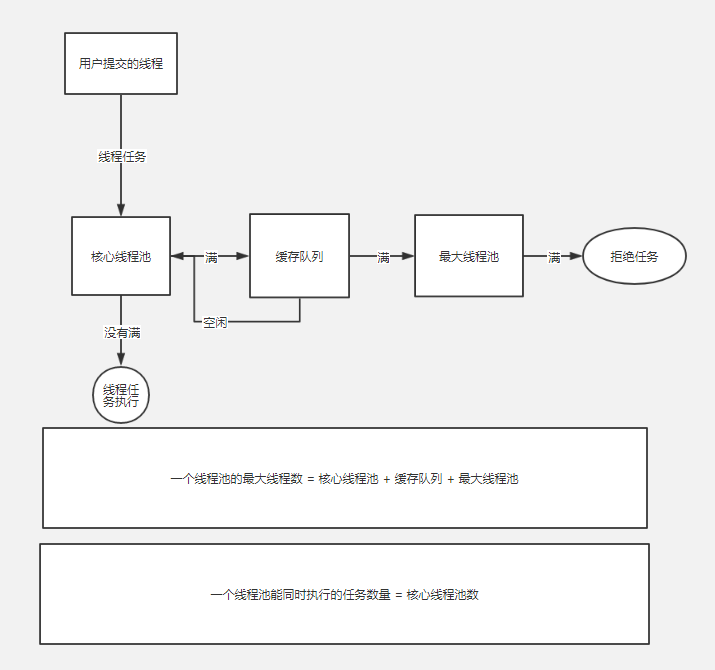
线程池种类
预定义线程池
FixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- corePoolSize 与 maximumPoolSize 相等,即其线程全为核心线程,是一个固定大小的线程池,是其优势;
- keepAliveTime = 0 该参数默认对核心线程无效,而 FixedThreadPool 全部为核心线程;
- workQueue 为 LinkedBlockingQueue(无界阻塞队列),队列最大值为Integer.MAX_VALUE。如果任务提交速度持续大余任务处理速度,会造成队列大量阻塞。因为队列很大,很有可能在拒绝策略前,内存溢出。是其劣势;
- FixedThreadPool 的任务执行是无序的。
适用场景:可用于Web服务瞬时削峰,但需注意长时间持续高峰情况造成的队列阻塞。
FixedThreadPool 代码 Demo:
import java.util.concurrent.*;
/**
* @author 郎家岭伯爵
* @time 2023/2/9 15:57
*/
public class ThreadPoolDemo {
public static void main(String[] args) {
// 创建固定大小的线程池,每次提交一个任务就创建一个线程,直到线程数量达到线程池的最大大小
ExecutorService executorService = Executors.newFixedThreadPool(8);
// 向线程池提交16个任务
for (int i = 0; i < 16; i++) {
final int taskId = i;
executorService.execute(() -> {
System.out.println("Task " + taskId + " is running");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
// 关闭线程池
executorService.shutdown();
}
}
输出结果:
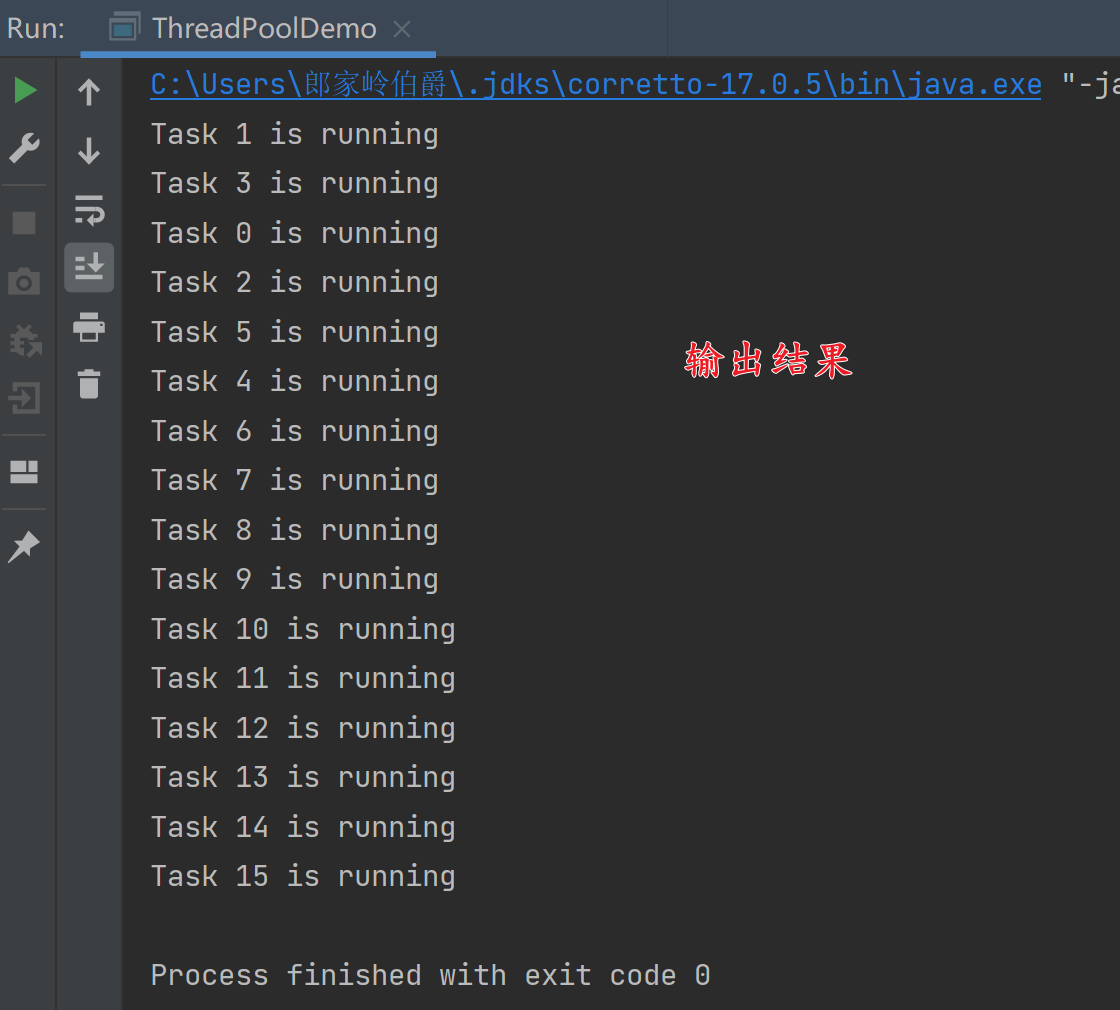
预定义线程池的创建方式基本是相同的,其核心语句为 ExecutorService executorService = Executors.newFixedThreadPool(8); 。不同类型的预定义线程池的传参略有不同。
CachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
- corePoolSize = 0,maximumPoolSize = Integer.MAX_VALUE,即线程数量几乎无限制;
- keepAliveTime = 60s,线程空闲 60s 后自动结束;
- workQueue 为 SynchronousQueue 同步队列,这个队列类似于一个接力棒,入队出队必须同时传递,因为 CachedThreadPool 线程创建无限制,不会有队列等待,所以使用 SynchronousQueue。
适用场景:快速处理大量耗时较短的任务,如 Netty 的 NIO 接受请求时,可使用 CachedThreadPool 。
SingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
咋一瞅,不就是 newFixedThreadPool(1) 吗?定眼一看,这里多了一层FinalizableDelegatedExecutorService 包装,这一层有什么用呢,写个 dome 来解释一下:
public static void main(String[] args) {
ExecutorService fixedExecutorService = Executors.newFixedThreadPool(1);
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) fixedExecutorService;
System.out.println(threadPoolExecutor.getMaximumPoolSize());
threadPoolExecutor.setCorePoolSize(8);
ExecutorService singleExecutorService = Executors.newSingleThreadExecutor();
// 运行时异常 java.lang.ClassCastException
// ThreadPoolExecutor threadPoolExecutor2 = (ThreadPoolExecutor) singleExecutorService;
}
对比可以看出,FixedThreadPool 可以向下转型为 ThreadPoolExecutor,并对其线程池进行配置,而 SingleThreadExecutor 被包装后,无法成功向下转型。因此,SingleThreadExecutor 被定以后,无法修改,做到了真正的 Single。
ScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
newScheduledThreadPool 调用的是 ScheduledThreadPoolExecutor 的构造方法,而 ScheduledThreadPoolExecutor 继承了 ThreadPoolExecutor,构造是还是调用了其父类的构造方法。
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
自定义线程池
以下是自定义线程池,使用了有界队列,自定义 ThreadFactory 和拒绝策略的 Demo:
import java.io.IOException;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class Test {
public static void main(String[] args) throws InterruptedException, IOException {
int corePoolSize = 2;
int maximumPoolSize = 4;
long keepAliveTime = 10;
TimeUnit unit = TimeUnit.SECONDS;
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(2);
ThreadFactory threadFactory = new NameTreadFactory();
RejectedExecutionHandler handler = new MyIgnorePolicy();
ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, unit,
workQueue, threadFactory, handler);
executor.prestartAllCoreThreads(); // 预启动所有核心线程
for (int i = 1; i <= 10; i++) {
MyTask task = new MyTask(String.valueOf(i));
executor.execute(task);
}
System.in.read(); //阻塞主线程
}
static class NameTreadFactory implements ThreadFactory {
private final AtomicInteger mThreadNum = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r, "my-thread-" + mThreadNum.getAndIncrement());
System.out.println(t.getName() + " has been created");
return t;
}
}
public static class MyIgnorePolicy implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
doLog(r, e);
}
private void doLog(Runnable r, ThreadPoolExecutor e) {
// 可做日志记录等
System.err.println( r.toString() + " rejected");
// System.out.println("completedTaskCount: " + e.getCompletedTaskCount());
}
}
static class MyTask implements Runnable {
private String name;
public MyTask(String name) {
this.name = name;
}
@Override
public void run() {
try {
System.out.println(this.toString() + " is running!");
Thread.sleep(3000); //让任务执行慢点
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public String getName() {
return name;
}
@Override
public String toString() {
return "MyTask [name=" + name + "]";
}
}
}
输出结果如下:

定制线程数量
首先要说明一点,定制线程池的线程数并不是多么高深的学问,也不是说一旦线程数设定不合理,你的程序就无法运行,而是要尽量避免以下两种极端条件:
-
线程数量过大
这会导致过多的线程竞争稀缺的 CPU 和内存资源。CPU 核心的数量和计算能力是有限的,在分配不到 CPU 执行时间的情况下,线程只能处于空闲状态。而在JVM 中,线程本身也是对象,也会占用内存,过多的空闲线程自然会浪费宝贵的内存空间。 -
线程数量过小
线程池存在的意义,或者说并发编程的意义就是为了“压榨”计算机的运算能力,说白了就是别让 CPU 闲着。如果线程数量比 CPU 核心数量还小的话,那么必定有 CPU 核心将处于空闲状态,这是极大的浪费。
所以在实际开发中我们需要根据实际的业务场景合理设定线程池的线程数量,那又如何分析业务场景呢?我们的业务场景大致可以分为以下两大类:
-
CPU (计算)密集型
这种场景需要大量的 CPU 计算,比如加密、计算 hash 等,最佳线程数为 (CPU 核心数 + 1)。比如8核 CPU,可以把线程数设置为 9,这样就足够了,因为在 CPU 密集型的场景中,每个线程都会在比较大的负荷下工作,很少出现空闲的情况,正好每个线程对应一个 CPU 核心,然后不停地工作,这样就实现了最优利用率。多出的一个线程起到了备胎的作用,在其他线程意外中断时顶替上去,确保 CPU 不中断工作。其实也大可不必这么死板,线程数量设置为 CPU 核心数的 1 到 2 倍都是可以接受的。 -
I/O 密集型
比如读写数据库,读写文件或者网络读写等场景。各种 I/O 设备 (比如磁盘)的速度是远低于 CPU 执行速度的,所以在 I/O 密集型的场景下,线程大部分时间都在等待资源而非 CPU 时间片,这样的话一个 CPU 核心就可以应付很多线程了,也就可以把线程数量设置大一点。线程具体数量的计算方法可以参考 Brain Goetz 的建议:
假设有以下变量:
- Nthreads = 线程数量
- Ncpu = CPU 核心数
- Ucpu = 期望的CPU 的使用率 ,因为 CPU 可能还要执行其他任务
- W = 线程的平均等待资源时间
- C = 线程平均使用 CPU 的计算时间
- W / C = 线程等待时间与计算时间的比率
这样为了让 CPU 达到期望的使用率,最优的线程数量计算公式如下:
Nthreads = Ncpu * Ucpu* ( 1 + W / C )。
CPU 核心数可以通过以下方法获取:
int N_CPUS = Runtime.getRuntime().availableProcessors();
当然,除了 CPU,线程数量还会受到很多其他因素的影响,比如内存和数据库连接等,需要具体问题具体分析。
总结
使用线程池创建多线程大致分为 预定义线程池 和 自定义线程池 两种方式,不过本质上都是使用 ThreadPoolExecutor 创建的。